728x90
반응형
JOIN문?
여러 테이블에 흩어져 있는 데이터를 연관짓기 위해 사용한다.
각 테이블에는 매칭할 수 있는 'key column'이 있어야 한다.
즉 여러 개의 테이블을 연관지어 데이터를 조합하고 하나의 테이블로 표현하기 위한 수단이다.
JOIN문의 default 값
JOIN 키워드만 사용하는 구문에 해당하는 JOIN은 'INNER JOIN'이다.
JOIN문 예시 테이블
- TABLE1
| ID | FOOD |
|---|---|
| 1 | 돈까스 |
| 2 | 곱창 |
| 3 | 삼겹살 |
| 4 | 치킨 |
- TABLE2
| ID | FOOD |
|---|---|
| 1 | 마라탕 |
| 2 | 돈까스 |
| 3 | 햄버거 |
| 4 | 곱창 |
JOIN문 종류
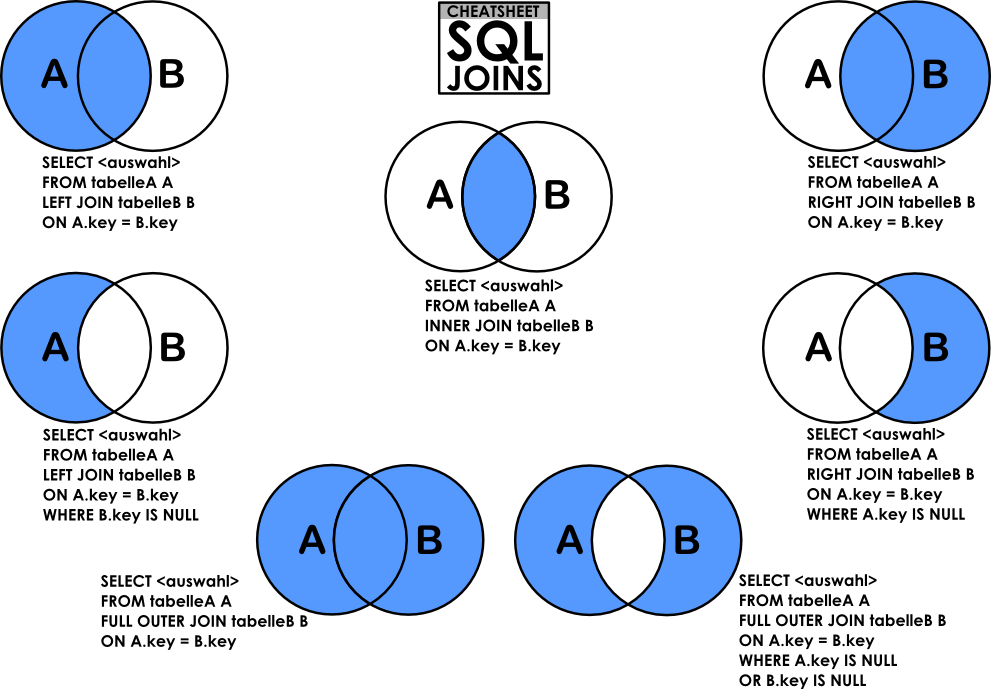
1. INNER JOIN
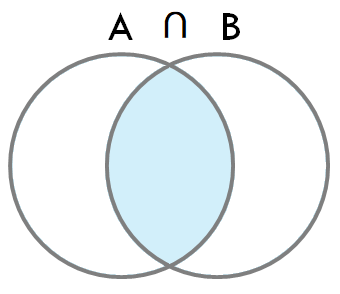
- 결과는 두 테이블 A, B의 A ∩ B 와 같다.
- 두 테이블 간의 교집합(key column)이 존재하는 경우에만 사용 가능하다.
- 조인하려는 두 테이블명을 JOIN을 기준으로 양쪽에 쓴다.
- 교집합이 되는 각 테이블의 컬럼명을 ON 또는 WHERE로 명시한다.
SELECT * FROM TABLE1 INNER JOIN TABLE2 WHERE TABLE1.col = TABLE2.col SELECT * FROM TABLE1 INNER JOIN TABLE2 ON TABLE1.col = TABLE2.col
1-1. THETA JOIN
- THETA JOIN을 사용하면 theta(θ)가 나타내는 조건에 따라 두 테이블을 병합할 수 있다.
- 모든 비교 연산자에서 작동한다.
- JOIN 작업의 일반적인 경우를 THETA JOIN이라고 한다.
1-2. EQUI JOIN / NON-EQUI JOIN
- EQUI JOIN (등가 조인)
- JOIN 조건식에 '='연산자를 사용한다.
- 주로 특정 테이블의 컬럼 정보를 알고 있고 그것에 대한 다른 테이블의 정보를 알고 싶을 때 사용한다.
- NON-EQUI JOIN (비등가 조인)
- JOIN 조건식에 '='연산자 이외에 비교 연산자를 사용한다.
1-3. NATURAL JOIN
- 자연 조인은 등가 조인하는 방법 중 하나이고 비교 연산자를 사용하지 않는다.
- 동일한 타입과 이름을 가진 컬럼을 JOIN 조건으로 이용한다.
- 반드시 두 테이블간의 동일한 타입과 이름을 가진 컬럼이 필요하다.
- 조인에 이용되는 컬럼은 명시하지 않아도 자동으로 사용된다.
- 조인하는 테이블 간의 동일 컬럼이 SELECT 절에 기술되어도 테이블 이름을 생략해야 한다.
- USING 절에는 조인 컬럼을 괄호로 묶어서 표현해야 한다.
2. OUTER JOIN

- 두 테이블 간의 합집합, 차집합 개념이다.
- '기준 테이블'과 '대상 테이블'이 존재한다.
- 기준 테이블) Driving table:드라이빙 테이블, 조인 대상 테이블 중 먼저 액세스하는 테이블을 말하며 Outer table이라고도 한다.
- 대상 테이블) Driven-to table:드리븐 테이블, 조인 대상 테이블 중 나중에 액세스하는 테이블을 말하며 Inner table 이라고도 한다.
- 기준 테이블은 변형이 없고, 대상 테이블이 변형된다.
-
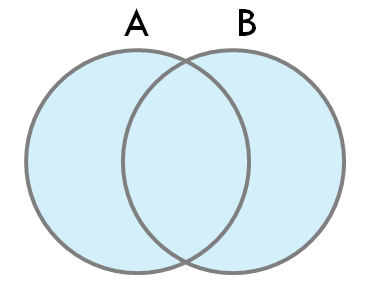
- 2-1. FULL OUTER JOIN
- 결과는 두 테이블 A, B의 A∪B 과 같다.
2-2. LEFT OUTER JOIN
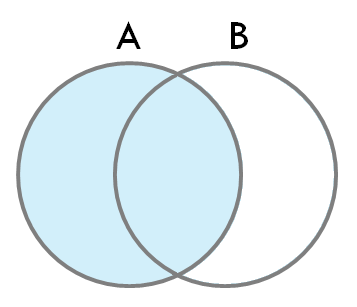
- 결과는 두 테이블 A, B의 (A ∩ B) ∪ (A - B) 와 같다.
- 'LEFT JOIN'이라고 부르기도 한다.
- 기준 테이블을 왼쪽에 두고 OUTER JOIN을 수행한다.
2-3. RIGHT OUTER JOIN
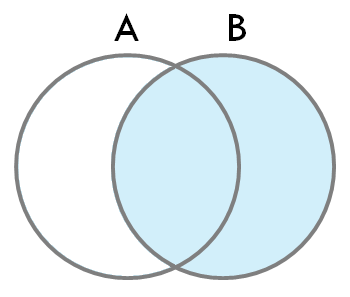
- 결과는 두 테이블 A, B의 (A ∩ B) ∪ (B - A) 와 같다.
- 'RIGHT JOIN'이라고 부르기도 한다.
- 기준 테이블을 오른쪽에 두고 OUTER JOIN을 수행한다.
2-3. LEFT ONLY / RIGHT ONLY
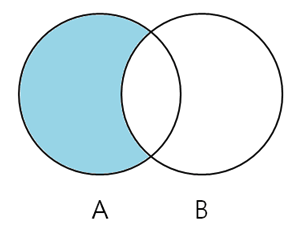
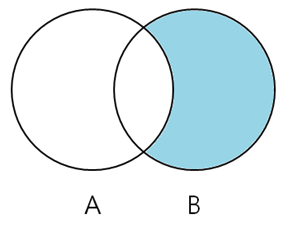
- 결과는 두 테이블 A, B의 (A - B) / (B - A) 와 같다.
- 테이블 A / B를 기준으로 B / A와 맵핑 되는 컬럼이 있다면 제외하고 추출한다.
다음 예시는 'LEFT ONLY'이고, col2는 테이블 A, B의 교집합 중 B가 존재하는 컬럼이다.
SELCT *
FROM TABLE1 A
LEFT OUTER JOIN TABLE2 B
ON A.col1 = B.col1
WHERE B.col2 IS NULL;3. CROSS JOIN
- 교차 결합을 위한 JOIN이다.
- JOIN 조건을 주지 않는 경우 (테이블 A의 행 갯수) * (테이블 B의 행 갯수)만큼 조회된다.
- Cartesian Product(카티션 곱) : 발생 가능한 모든 경우의 수를 출력
- 조인 조건을 생략하거나 조인 조건이 부적절한 경우에 발생한다.
- 데이터가 방대할 경우 CPU 과부화를 유발시킨다.
/* 명시적 CROSS JOIN */ SELECT * FROM TABLE1 CROSS JOIN TABLE2 /* 암시적 CROSS JOIN */ SELECT * FROM TABLE1, TABLE2
4. UNION
- UNION vs. JOIN
- 공통점 : 테이블의 데이터를 연결
- 차이점 : 연결하는 방법이 다름
- JOIN*
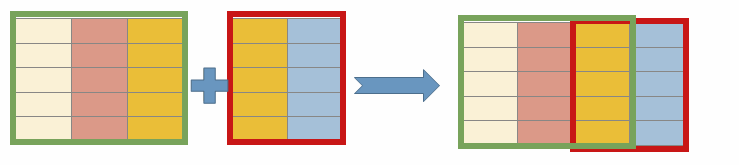
- UNION*
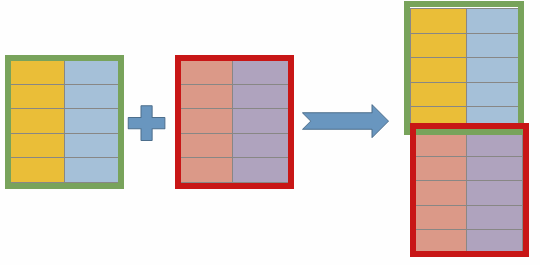
- 두 개 이상의 테이블을 JOIN하는 방법이다.
- 연결하고자 하는 컬럼의 갯수와 타입이 같아야 연결할 수 있다.
- UNION이 모든 결과를 합치기 때문에 정렬은 마지막에 한 번만 가능하다.
- UNION은 중복 데이터 값을 삭제하고 연결한다.
- UNION ALL을 사용하면 중복되는 값도 모두 연결한다.
SELECT name FROM TABLE1 UNION SELECT name FROM TABLE2 UNION SELECT name FROM TABLE3 ORDER BY name;
5. SELF JOIN
- 1개의 테이블에서 JOIN 하는 방법이다.
- FROM 절에 동일 테이블이 두 번 이상 나타난다.
- 자기 자신의 테이블로 JOIN을 실행하므로 테이블 별칭(Alias)을 사용해야 데이터 조회가 가능하다.
SELECT column_names FROM TABLE1 T1, TABLE2 T2 WHERE condition;
6. semi-join / anti-join
Conventional join이 아닌 Sub query를 이용하여 main body query를 driving 혹은 driven 하는 join이다.
/* Conventional join */
SELECT a.*
FROM employee a, dept b
WHERE a.deptid = b.deptid;6-1. semi-join
- JOIN 조건이 존재해야 한다.
- row들 중 outer node와의 JOIN 결과를 반환한다.
- SQL 구문 상 직접 기술할 수 없어, 'IN', 'EXISTS'등의 ANY형 연산자로 표현한다.
- 조건에 대한 index가 존재하고, inner node의 unique가 보장되면 'Inverted Semi Join'을 할 수 있다.
# 1 SELECT a FROM TABLE1 WHERE a+3 IN (SELECT C FROM TABLE2 WHERE d='d');
SELECT a.\*
FROM employee a
WHERE EXISTS (SELECT b.deptid
FROM dept b
WHERE b.deptid = a.deptid);
6-2. anti-join
- JOIN 조건에 부합하지 않는 outer node의 row들만 반환한다.
- 반드시 NULL 처리가 필요하다. (oracle 11 버전부터는 명시하지 않아도 가능)
SELECT a.\*
FROM employee a
WHERE NOT EXISTS (SELECT b.deptid
FROM dept b
WHERE b.deptid = a.deptid);
오라클에서는 Semi-join처럼 optimizer가 인식하기 위해 명확한 syntax는 없지만,
EXISTS/IN 또는 NOT EXISTS/NOT IN을 사용하면 Semi-join 또는 Anti-join으로 optimizer가 판단하게 된다.
JOIN algorithm
요약
- DBMS의 조인은 주로 1) 내부 조인 2) 외부 조인 두 가지가 있다.
- 내부 조인은 널리 사용되는 조인 작업이며 기본 조인 유형으로 간주할 수 있다.
- 내부 조인은 세 가지 하위 유형으로 더 나뉜다. 1) 세타 조인 2) 자연 조인 3) EQUI 조인
- Theta Join을 사용하면 theta가 나타내는 조건에 따라 두 테이블을 병합할 수 있다.
- 세타 조인이 동등성 조건만 사용하면 동등 조인이 된다.
- 자연 조인은 비교 연산자를 사용하지 않는다.
- 외부 조인에서는 두 조인 테이블의 각 레코드가 일치하는 레코드를 가질 필요가 없다.
- 외부 조인은 1) 왼쪽 외부 조인 2) 오른쪽 외부 조인 3) 완전 외부 조인의 세 가지 하위 유형으로 더 나뉜다.
- LEFT Outer Join은 오른쪽 테이블에서 일치하는 행이 없더라도 왼쪽 테이블의 모든 행을 반환한다.
- RIGHT Outer Join은 왼쪽 테이블에서 일치하는 행이 없더라도 오른쪽 테이블의 모든 열을 반환한다.
- 완전 외부 조인에서는 일치 조건에 관계없이 두 관계의 모든 튜플이 결과에 포함된다.
Referenece
반응형
'[DB]DataBase > [SQL]' 카테고리의 다른 글
| [SQLD] 데이터베이스 스키마 구조 (0) | 2024.02.21 |
|---|---|
| [SQLD] 데이터 독립성 (0) | 2024.02.20 |
| [SQLD] 데이터 모델링 (0) | 2024.02.19 |
| [SQL] CONVERT_TZ() (0) | 2023.07.14 |
| [SQL] 집계함수(Aggregate function) (0) | 2023.04.15 |


